The Problem
Microservices:
The software architecture of most large internet services, if not all, consists of microservices. Microservices are fine-grained components of the system, each with a particular functionality, which communicate via lightweight protocols. Systems nowadays consist of several such microservices, interconnected by large hierarchies of dependencies. In order to program software in these microservice-based architectures, software engineers need to use complex libraries to manage the interaction. If performance and latency are vital, as is in many cases, programmers must also implement efficient concurrent system calls, and leverage difficult-to use synchronization methods, like locks or futures.
 Internet services are composed
of hundreds of interlinked microservices (source:
http://contiv.github.io/articles/microservice-challenge-b139e7b3.jpg)
Internet services are composed
of hundreds of interlinked microservices (source:
http://contiv.github.io/articles/microservice-challenge-b139e7b3.jpg)
{kind=link}
Handling I/O:
A particularly important task performed by many microservices are I/O operations, e.g., to a database or other data stored on disk. Compared to much of the usual computation in these systems, the latency incurred through I/O usually dominates the latency of the whole system. For this reason, it is particularly important to optimize I/O as much as possible. Many I/O-based services allow batched calls, e.g. to retrieve an array of data points from a database, instead of a single one. When several I/O calls to different places are issued, it is crucial to know how they depend on each other. Independent calls can be executed concurrently, significantly reducing latency, whereas dependent ones have to be executed in sequence if the service is to operate correctly.
Getting this right: very complex code
Managing the different microservice protocols, while writing code that executes correctly and efficiently, is a daunting task. In practice, it usually forces a trade-off between readability, maintainability and efficiency: To improve efficiency, the developer has to explicitly manage I/O calls and concurrency, at the cost of code readability and maintainability. On the one hand, blocking (synchronous) I/O calls produce the most readable and maintainable code but result in a sequential execution of all requests. On the other hand, non-blocking (asynchronous) I/O calls execute remote services in parallel but require the use of concurrency constructs such as threads or events. Threads use locks which can introduce deadlocks, while events clutter the code significantly. Thus, both approaches add additional complexity and result in code that is much less clean and concise.
Ÿauhau
To overcome these problems, we present Ÿauhau. It allows engineers to write simple code that is maintainable and concise, without sacrificing the efficiency of batching and concurrent I/O calls.
Simple programming
Ÿauhau is an extension to the Ohua framework. Ohua is an EDSL (embedded domain specific language) in Clojure, a dialect of Lisp for the JVM. Programs written with Ÿauhau are simple because of the declarative, functional nature of LISP. A programmer does not need to think about what is executed when, nor label dependencies or introduce complex constructs for concurrency and parallelism. Instead, programmers using Ÿauhau only need to write their algorithm in a simple, declarative style and the complier takes care of squeezing out efficiency when executing.
Efficient execution
When the Ohua compiler reads an Ohua program, it uses analysis methods to understand what can be executed concurrently, and what cannot. It does so by leveraging the declarative nature of the programs, without any explicit input from the programmer. Ohua automatically executes applications using all the concurrency and parallelism extracted, managing synchronization itself. On top of Ohua, the Ÿauhau extensions understand which calls perform I/O and automatically batch all I/O calls to the same source, if it allows batching. In this way, Ÿauhau allows programmers to write simple code which automatically works with close to maximal I/O efficiency.
Example: Loading the contents for a blog
Consider a service that loads the webpage for a blog written as an Ohua algorithm:
; Algorithm definition:
;(delalgo algo-name [args] (fn-call ))
(defalgo blog []
(let [lp (left-pane )
mp (main-pane )
rlp (render-left-pane lp)
mlp (redner-main-pane mp)]
(render-page rlp mlp))
Note that the only difference in terms of programming style is the use
of defalgo to declare an algorithm instead of defn to declare a
function. Our blog service now needs to request data, such as the posts
on the blog and their according meta data from another service, i.e., it
performs I/O. In Ÿauhau, we write this as follows:
(defalgo getPostIds [] (fetch (req-post-ids )))
(defalgo getPostInfo [postId] (fetch (req-post-info postId)))
(defalgo getPostContent [postId] (fetch (req-post-content postId)))
The algorithms inside the blog such as the one to compute the content
of the main panel can now use these calls:
(defalgo main-pane []
(let [postIds (getPostIds )
postInfos (smap getPostInfo postIds)
latestPostInfos (take-latest postInfos 10)
latestPostIds (get-ids latestPostInfos)
latestPostContents (smap getPostContent latestPostIds)]
(zip latestPostInfos latestPostContents)))
The (stateful) functions that the algorithm uses maybe defined either in Java as a function inside a class
public class LatestPosts {
@defsfn
public List<PostId> getIds(List<PostInfo> postInfos){
return postInfos.stream().map(PostInfo::getId).collect(Collectors.toList());
}
}
or in Clojure as a normal function
(defn take-latest [^Iterable posts
^Number n]
(let [res (take n (sort-by (fn [post] (.getDate post)) posts))]
res))
or as a function inside a Scala class. Choose whatever language you prefer.
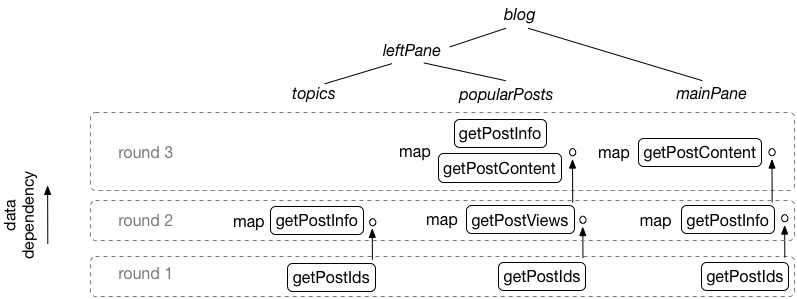 A graph of the I/O operations in
the blog example.
A graph of the I/O operations in
the blog example.
The above graph depicts the use of the algorithms that fetch data from
other services in the whole blog program. Note for example that 3
requests would be issued to get the ids of the posts because the
getPostIds algorithm is called in 3 different parts (popular-posts,
topics, main-pane) of the program. Ÿauhau instead only issues a
single request.
There is an old implementation for yauhau in Java, however we have made a revised implementation which curretly only works with Haskell. We do intend to provide a Java/Clojure compatible adapter soon.
For now you can find the Haskell yauhau project
here and the blog example
described in the section before
here.
The examples directory also contains a readme on how to run and
experiment with the blog example.
How does it work?
Ohua: Implicit concurrency and parallelism through dataflow
Ohua compiles a Clojure-style program into a so-called dataflow graph. Such a graph represents the different functions and algorithms in the computation and the dependencies between the produced data.
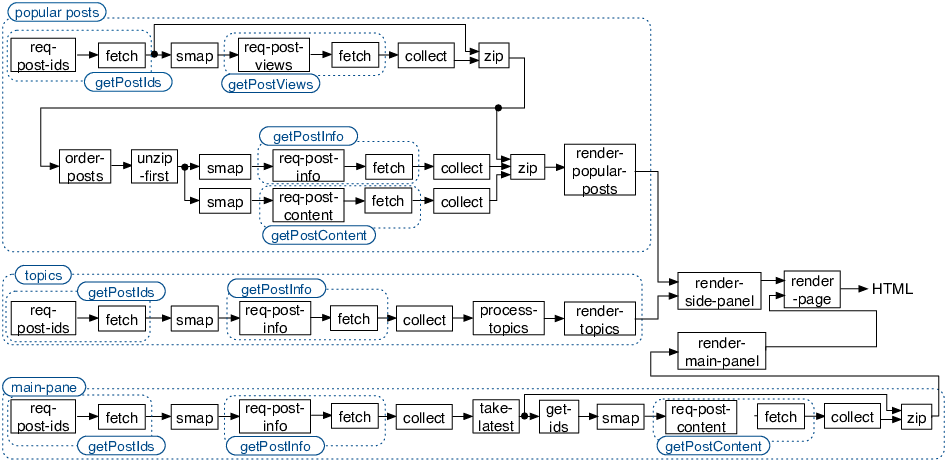 The dataflow graph
generated by Ohua for the blog example.
The dataflow graph
generated by Ohua for the blog example.
Ÿauhau: Program rewrites<a id=”ÿauhau-program-rewrites”name=”ÿauhau-program-rewrites”></a>
In order to execute I/O calls efficiently, Ÿauhau uses a series of rewrites on an intermediate representation of the program that allow it to batch I/O calls to the same source whenever possible, while maintaining the functionality of the program.
 The program transformation to
reduce the number of times the post ids are fetched from 3 to 1
visualized with data flow graph.
The program transformation to
reduce the number of times the post ids are fetched from 3 to 1
visualized with data flow graph.
Some benchmarks
Similar to Ÿauhau, there are other frameworks which attempt to batch calls together and minimize the cost of I/O. Haxl, by Facebook, does so using a concept called “Applicative Functors” in Haskell. Muse is a similar library, based on Haxl, for Clojure. Finally, Stitch, by Twitter, also provides a similar functionality to Haxl, Muse and Ÿauhau. Since Stitch is closed-source, we compare Ÿauhau only to Haxl and Muse.
Baseline Comparison
We compare Ÿauhau to Haxl, Muse, and for reference, to a sequential execution. We do this using randomly generated microservice-based applications, with so-called “level graphs”. The number of levels of a graph represent the total complexity of the application. The more levels, the larger and more complex the application. Ÿauhau consistently performs better than all other systems, or at least as good in all cases.
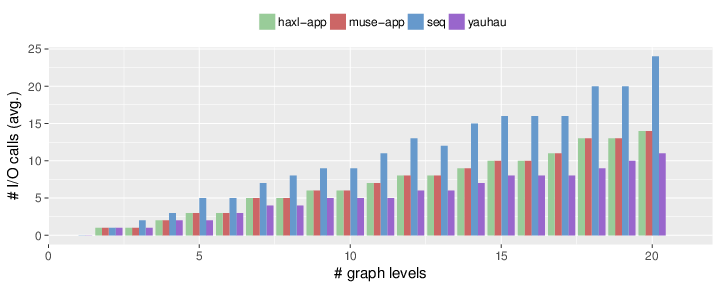
Comparison of Ÿauhau, Muse and Haxl. Ÿauhau consistently outperforms other frameworks, especially in more complex applications (more “levels” in the graph).
Code Style
Haxl and Muse allow for different styles of coding, an “Applicative” style (named after Applicative Functors, mentioned above), or a “Monadic” style. The latter is simpler to write, but as can be seen in the graph, results in worst performance. Except for Ÿauhau, which achieves the best performance of all systems, independent of the code style.
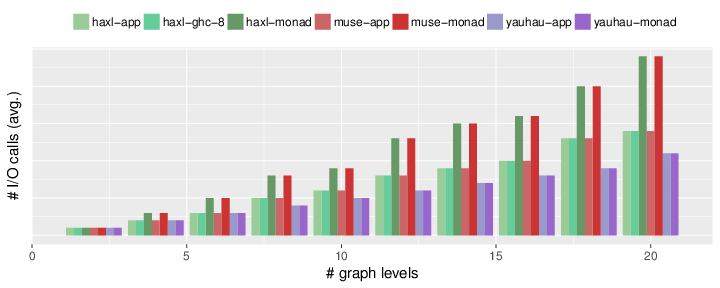
Ÿauhau’s performance is independent of the code style, unlike other frameworks.
I/O imbalance
Not all sources of I/O are equal. When one microservice requires too long to execute in comparison to the rest, most systems’ performance will suffer an additional penalty. This happens because these systems execute I/O calls in rounds, and block the execution until all I/O calls in a round have been executed. Not Ÿauhau. The dataflow execution model allows a Ÿauhau program to continue executing everything that can be executed while waiting for a particularly laggy I/O call to finish.
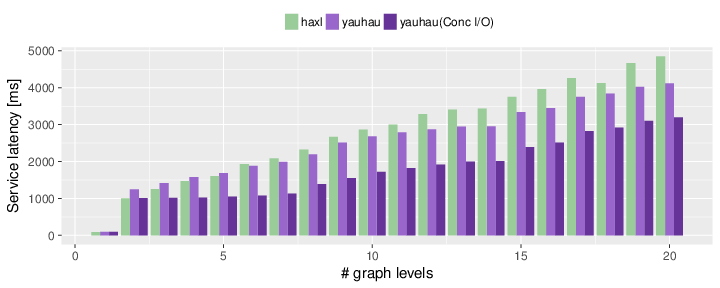
Ÿauhau’s execution is not blocked by a microservice with large latency, unlike other frameworks.
Modular designs
Maintainable and debuggable software has to be written in a modular fashion. This is usually done by writing functions, grouping them into libraries, and reusing the functionality. However, in the other systems, this leads to worse execution behavior. Haxl struggles to understand some dependencies that go beyond the borders of a function, and Muse doesn’t do it at all. Ÿauhau with its dataflow model, on the other hand, can extract the dependencies with surgical precision. To measure this, instead of making the application more complex, we took a single large application and added more calls to other functions in the random graphs, with different probabilities. The result is an application that has more calls to other functions in its body. We see that for Ÿauhau, this does not change the number of calls significantly (it changes at all because of the random nature of the experiment), whereas Haxl and Muse struggle with more function calls.
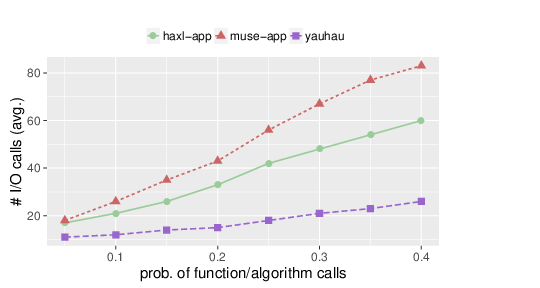
Ÿauhau understands and considers dependencies across functions, where others struggle.